
The Same Tools, Pointed Differently
On open-source AI music tutors, the structural erasure of music education, and what it means when the wand finally belongs to everyone

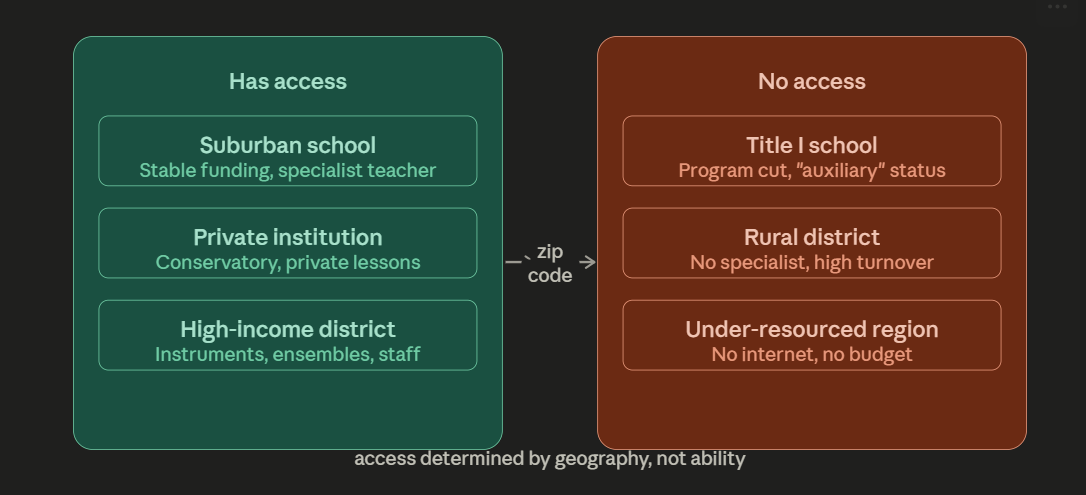
The school didn’t lose its music program in a single dramatic vote. That is rarely how it happens. What happened instead was quieter and more durable: the district reclassified instrumental instruction as “auxiliary,” which is the bureaucratic word for expendable. A spreadsheet somewhere decided that a trumpet teacher cost more than the line item could bear. The students who had been waiting the quiet child who was going to find herself in that room, the boy who didn’t know yet that he could sing they didn’t lose a program. They lost a version of themselves that was never allowed to exist. That is the actual cost. The budget saved a salary. The community lost a future.
This is not hyperbole. It is the documented pattern that researchers at the National Association for Music Education have tracked across decades of Title I school data, rural district surveys, and the grim correlations between zip code and access to arts instruction. The paper before me an academic survey of open-source AI music tutors for underfunded classrooms begins with this pattern and then makes a claim that, until very recently, would have sounded like optimism performing as analysis: the same tools that power the world’s most sophisticated music technology companies can now run on a Raspberry Pi 5, cost less than a used textbook, and deliver real-time pitch correction and music theory feedback to a student in a remote village who has never met a professional musician in her life.
I want to sit with that for a moment before I explain why it matters and where it gets complicated.
What $5 Buys Now
The cost collapse in AI music production from $75,000–$150,000 per professional track to approximately $5 in API credits has been Musinique’s central economic argument for several years. But the paper under review is making an adjacent and equally significant claim about a different kind of cost: the cost of instruction. What does it cost to give a child meaningful, research-grade feedback on whether she is holding the pitch? Whether her rhythm is landing on the beat? Whether the note she just played was the one written?
For most of human history, that feedback cost the presence of a human expert. The expert had to be trained, licensed, recruited to an underfunded district where the pay was low and the turnover was predictable. The “hierarchy of prestige” the paper describes where rural and Title I positions are entry points on the way to “bigger and better” suburban programs meant that even the students who briefly had a music teacher often lost her within a year or two. The expertise was rented, not owned. The program built around a single person’s institutional knowledge collapsed when that person left.
What CREPE, Omnizart, and the Raspberry Pi ecosystem are collectively offering is something different: expertise that does not leave. A system that can identify pitch errors at 20-cent resolution finer than most human ears that runs offline, that does not require a subscription, that can be deployed in a school with no reliable internet connection and no technology budget beyond the one-time cost of a $125 board. The paper’s Total Cost of Ownership analysis is blunt: for 100,000 inference calls per day, the transition from cloud to local hardware pays for itself in three months. After that, the school owns the tool.
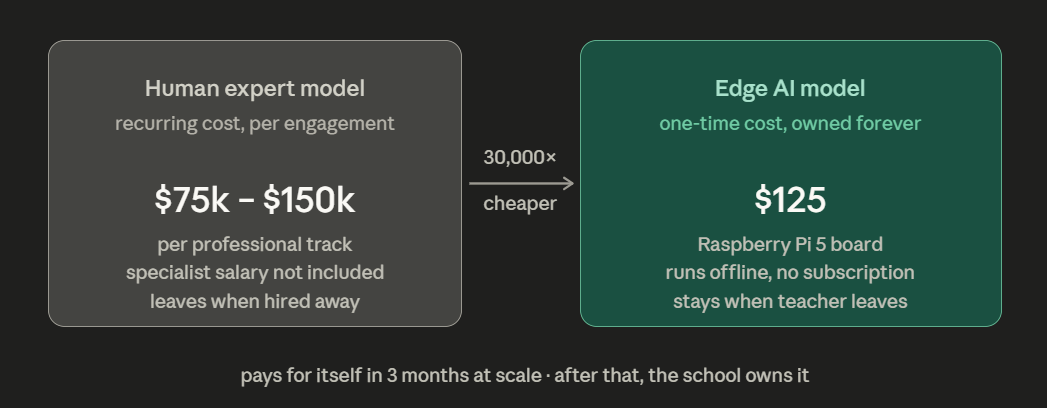
This is not a small thing. This is the elimination of the economic barrier that kept research-grade music instruction locked inside institutions that could afford human experts and stable internet connections. Whether the tool is actually as good as a human teacher whether it can hear the musicality underneath the technical error, whether it can tell the difference between a wrong note and a note played wrong on purpose is a genuine and unresolved question. But the question of whether it is better than nothing is easier. Nothing is what most of these students currently have.
The Platform Is Still Not Your Friend
Here is where I must complicate the optimism, because the paper is largely enthusiastic and enthusiasm without qualification is how good tools become bad policies.
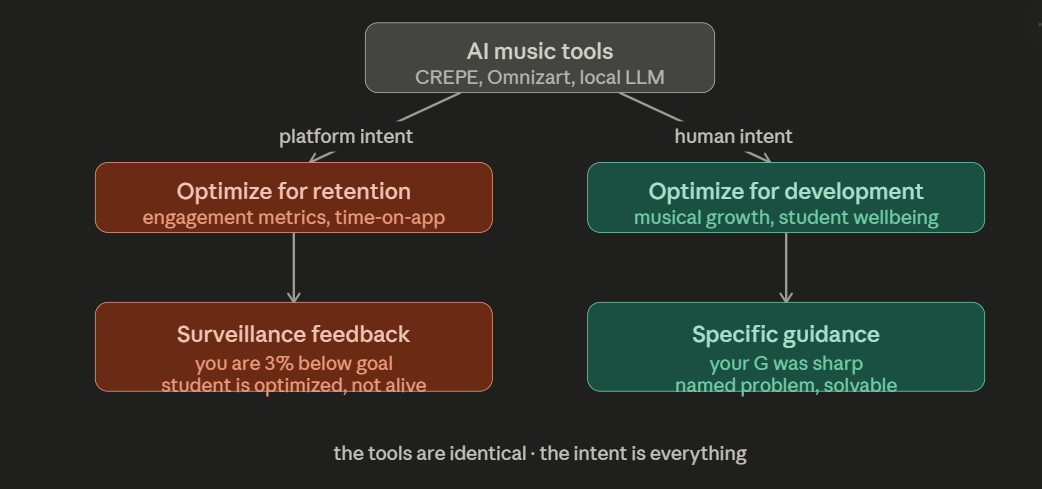
The research describes AI music tutors as providing “continuous, adaptive, data-driven feedback loops” that transform how instrumental skills are acquired. This is accurate as far as it goes. But there is a version of this story that is only technically different from what Spotify has been doing for years which is to say: using the tools of personalization to serve the platform rather than the student.
Consider: the paper notes that AI-assisted practice platforms support “self-regulated learning” by helping students set objectives, monitor performance, and reflect on progress. This is the language of behavioral modification at scale. The student who practices sixty minutes because an app told her she was 3% below her weekly goal is not the same student as the one who practiced because the music made her feel something she needed to feel again. The first student is optimized. The second student is alive.
This distinction matters because the systems being described Trala, Violy, the Omnizart pipeline, the CREPE pitch tracker are neutral tools in the precise sense that Musinique has always meant: they will do whatever the person deploying them has decided they should do. An AI music tutor built by a company optimizing for retention metrics will make different choices than one built by an educator optimizing for musical development. The pitch correction feedback that feels like helpful guidance in one context feels like surveillance in another. The “objective assessment” that empowers one student to improve demoralizes another who needed to hear that her phrasing was beautiful before she heard that her intonation was off.
The paper nods at this there is a section on avoiding “monoculture,” on the risks of unbalanced training data reinforcing existing biases, on the need for ethnomusicological collaboration to ensure “cultural fidelity.” What it does not say, plainly, is that these risks are not edge cases. They are the default mode of every technology that has been built at scale without the communities it serves at the center of its design.
The Raspberry Pi running a local AI music tutor in a Title I school in rural Mississippi is not the same thing as Spotify. But the architecture of incentives is identical unless someone builds the tool differently on purpose. The difference is not the tools. It is who controls the intent.
Champa Jaan’s Lullabies, and the Question of Whose Tradition
The paper includes a section on cultural diversity that is, in my view, the most important and least developed part of the entire survey. It notes, correctly, that “traditional notation systems often fail to capture the nuances of ornamentation, microtonality, and complex rhythmic patterns found in folk and indigenous traditions.” It notes that AI systems trained on diverse datasets can provide “automated style recognition and adaptive responses specific to these traditions.” It warns against “monoculture.”
What it does not fully reckon with is the specific shape of what has been lost and what would be required to recover it.
Champa Jaan was a tawaif a courtesan-musician of Lucknow’s kotha tradition, working in the early twentieth century. She was among the most formally trained musicians in India, a master of thumri and ghazal and Hindustani classical improvisation. She recorded eleven 78-rpm discs for Gramophone Company of India between 1918 and 1924. All are lost. Catalogue numbers survive. The music does not. Her lullabies persisted only because ethnomusicologists in the 1960s kept finding melodic fragments with Hindustani classical fingerprints that no one could trace to a source.
This is the tradition the paper is gesturing at when it speaks of “endangered oral traditions” and “non-Western musical cultures.” And here is the question that the paper’s optimism about AI training datasets does not answer: what do you train on when the recordings are gone? When the documentation was never made because the women who held the tradition were considered socially stigmatized rather than culturally essential? When the “diverse dataset” required to teach an AI the difference between a meend glide and a murki grace note does not exist because the colonial record-keeping apparatus decided the music wasn’t worth keeping?

The paper proposes that AI can “aid in the digital preservation of endangered oral traditions by documenting performance practices that were previously inaccessible to human transcription.” This is true and important. But preservation is not recovery. An AI tutor trained on the surviving fragments of Champa Jaan’s tradition can teach a student what those fragments contain. It cannot reconstruct what was lost. It cannot give back the eleven discs. It can only make the fragments available to the children who should have had them all along.
This is the hardest version of the democratization argument: we are building tools to make accessible what survived. What did not survive is the permanent record of who decided what was worth recording.
What the Zynthian Platform Actually Means
I want to say something specific about the Zynthian Open Synth Platform, because the paper describes it and then moves on, and I think it deserves more sustained attention.
Zynthian is a Raspberry Pi-based open-source synthesizer that costs between 400 and 500 euros in kit form. It supports more than thirty synthesis engines. It runs Pure Data, a visual programming environment. It can be built from scratch by a student who wants to understand how the device works rather than just how to use it. It is, in the paper’s phrase, a “Swiss Army knife” which undersells what it actually is.
What Zynthian represents is the integration of making and understanding in a single affordable object. The student who builds a Zynthian is not just learning to play an instrument. She is learning signal flow. She is learning how a synthesizer engine converts mathematical instructions into audible sound. She is learning the relationship between the physical world and the digital one that will structure her entire professional and creative life. She is learning, in the paper’s framing, both “musical and technical literacy” and she is learning them as aspects of the same activity rather than as separate disciplines that happen to share a room.
This is the “Learn AI by Doing AI” principle that Northeastern University professor Nik Bear Brown has built his entire pedagogical practice around, applied to music education. The tool is the curriculum. The building is the learning. The Zynthian doesn’t sit between the student and the knowledge; it is the knowledge made physical and manipulable.
For underfunded classrooms, this matters in a specific way: it replaces the single human expert the teacher who is the sole conduit of institutional knowledge with a system that distributes that knowledge into the device itself. When the Zynthian teacher leaves for the suburban district, the Zynthian stays. The students who learned by building it still know how it works. The knowledge is in them now, not borrowed from someone passing through.
The Pedagogy of Being Seen
There is a finding in the paper that I want to pull out of the subsection where it is buried and place at the center of the argument, because it is the most important thing the research demonstrates.
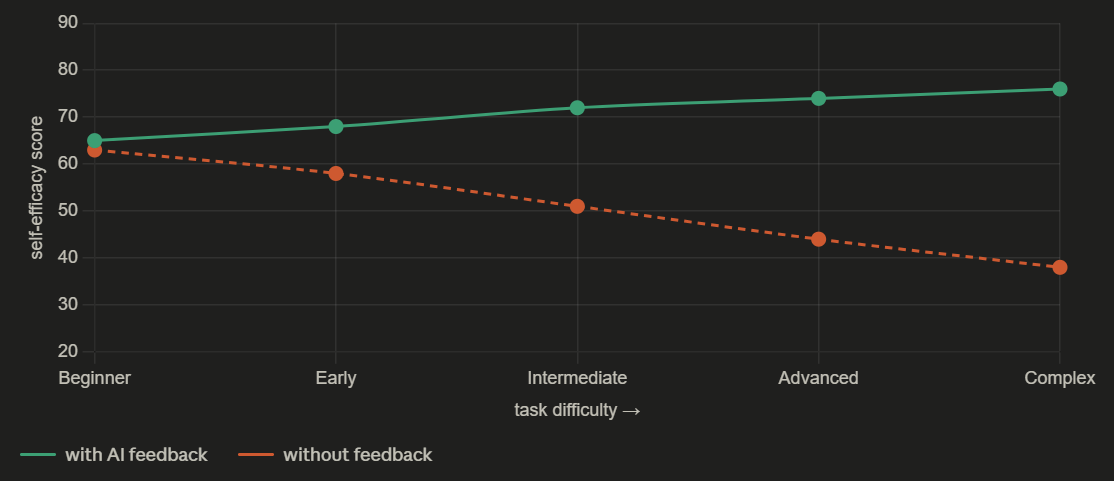
Students using AI-assisted practice platforms show “stable or increasing levels of Music Learning Self-Efficacy, even as task difficulty increases.” Control groups students without AI feedback tools “experience a decline in confidence as they encounter more challenging material without immediate support.”
Translated: the student who gets immediate, specific feedback on whether she is playing the right note is more likely to believe she can eventually play the right note than the student who gets no feedback at all. This is not a surprising finding. It is a precise description of what it feels like to be seen versus to be invisible.
The child who is told, by a tool that is paying specific attention to her specific performance at this specific moment, that her G was sharp that child has been heard. She knows what to fix. The problem is named. Named problems are solvable problems. The child who plays into silence who has no teacher, no feedback, no way of knowing whether what she did was right or wrong that child eventually concludes that the problem is her. That she is not musical. That music is not for her.
The AI pitch tracker does not replace the human music teacher. It cannot hear the musicality underneath the technical error. It does not know that her phrasing was beautiful. But it tells her, immediately and specifically, that her G was sharp. And that the specific, named, solvable feedback is often the difference between the child who keeps going and the child who stops.
The most democratized version of this technology is not the one with the most sophisticated AI. It is the one that makes the specific visible to the most students who would otherwise receive only silence.
What We Are Actually Building
The paper concludes with three recommendations: prioritize edge-based procurement, invest in teacher-centric AI training, mandate cultural inclusivity in datasets. These are correct recommendations. They are also insufficient unless someone is honest about what they require.
Prioritizing edge-based procurement means telling school administrators that a one-time hardware cost is better than a recurring subscription cost, even when the budget conversation happens in a political environment where capital expenditures require board votes and operating costs can sometimes be absorbed. This is not a technology argument. It is a governance argument. It requires someone to make it.
Investing in teacher-centric AI training means treating music teachers as the professionals they are rather than as technophobes who need to be brought up to speed. The Experience AI program the paper cites the Raspberry Pi Foundation and Google DeepMind collaboration is a genuine contribution. But professional development for music teachers in Title I schools competes for time and money with everything else those teachers are already being asked to do. The training is only useful if there is time for it.
Mandating cultural inclusivity in datasets is the most urgent and the most politically complicated recommendation in the paper. The mandate requires someone with power over funding to use that power in favor of traditions that have historically been excluded from the archives that AI systems train on. This is not a technical problem. It is a political one. It requires people who control research funding to decide that the Champa Jaan problem the problem of what to do when the recordings are gone because the recordkeepers decided they weren’t worth keeping is their problem too.
The tools exist. The cost has collapsed. The Raspberry Pi runs the model. The Zynthian teaches itself. The question is only intent: who gets to decide what the tools are for, and who they serve, and whose traditions they carry forward.
Champa Jaan’s lullabies survived. They are available now. The next question is whether the AI music tutor built for the Title I school in rural Mississippi will know how to teach them and whether anyone will decide that building a system capable of that is worth the work.
It is. Here is why: because the child waiting in that classroom is waiting for the specific. The specific voice. The specific tradition. The specific note, named correctly, in the moment she played it wrong and needed to know.
The tools can do this. The only remaining question is whether we will point them at her.
musinique.com | humanitarians.ai | musinique.substack.com
Tags: open-source AI music education edge deployment, democratizing music instruction underfunded schools, Raspberry Pi Zynthian music tutor, cultural bias AI music training data, Lyrical Literacy neurobiological music pedagogy